As robotic systems become increasingly integrated into real-world environments, ranging from autonomous
vehicles to household assistants, they inevitably encounter diverse and unstructured scenarios that lead
to failures. While such failures pose safety and reliability challenges, they also provide rich perceptual
data for improving system robustness. However, manually analyzing large-scale failure datasets is
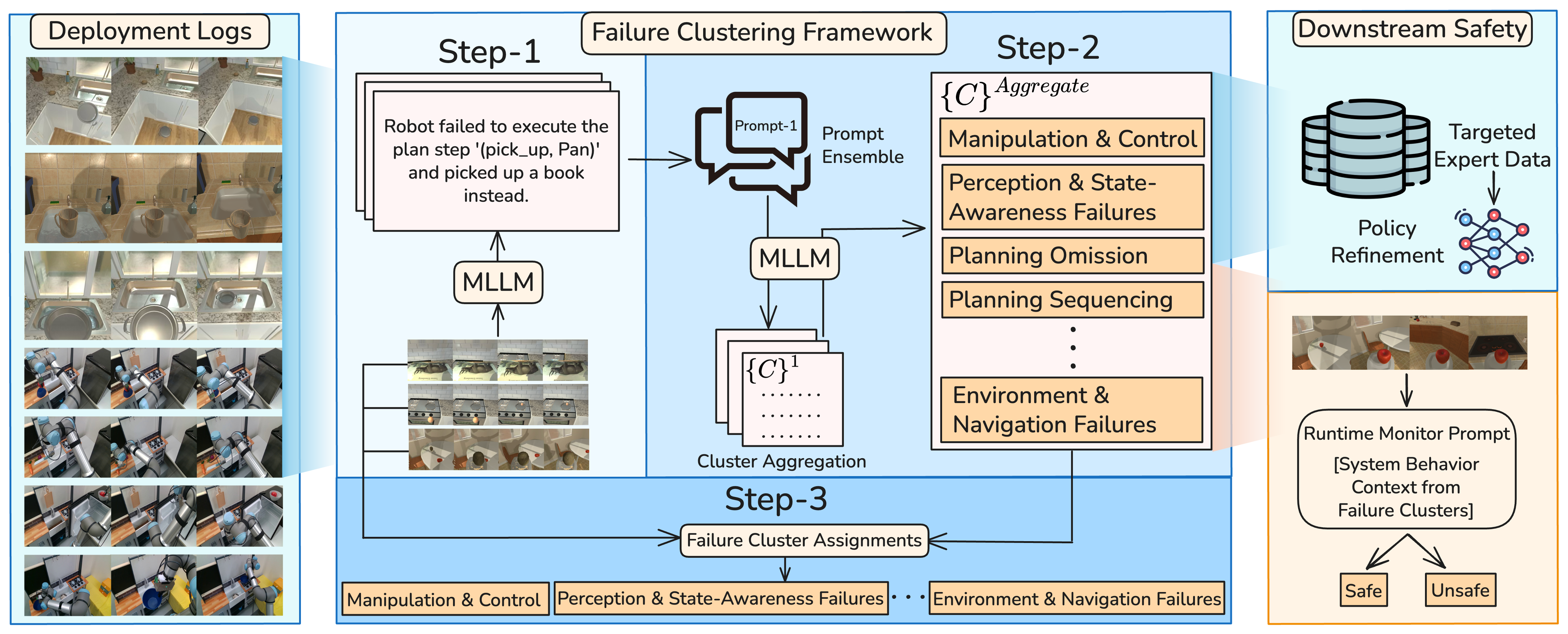
impractical and does not scale. In this work, we introduce the problem of unsupervised discovery of
failure taxonomies from large volumes of raw failure logs, aiming to obtain semantically coherent and
actionable failure modes directly from perceptual trajectories. Our approach first infers structured
failure explanations from multimodal inputs using vision-language reasoning, and then performs clustering
in the resulting semantic reasoning space, enabling the discovery of recurring failure modes rather than
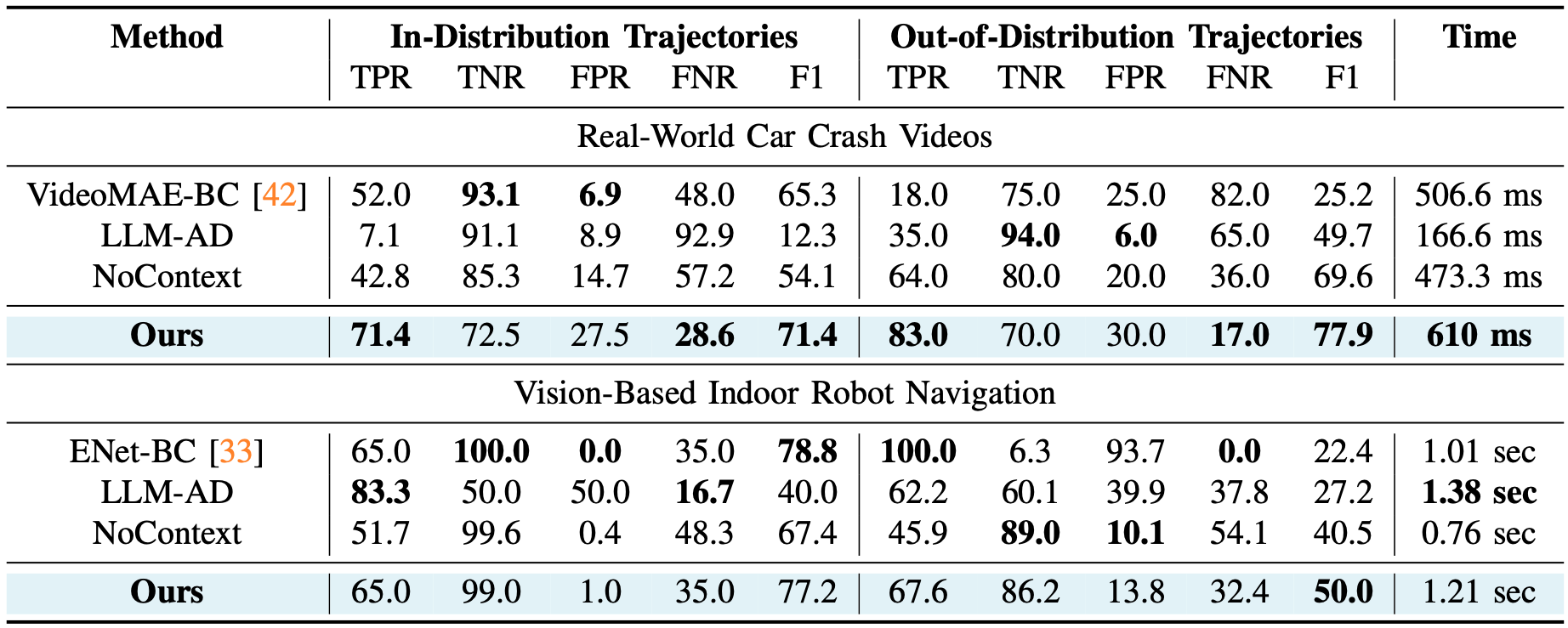
isolated episode-level descriptions. We evaluate our method across robotic manipulation, indoor
navigation, and autonomous driving domains, and demonstrate that the discovered taxonomies are consistent,
interpretable, and practically useful. In particular, we show that structured failure taxonomies guide
targeted data collection for offline policy refinement and enhance runtime failure monitoring systems.